
Transform Dates and Ensure Data Quality With Databricks & PySpark
Introduction
Messy date formats can wreak havoc on your data pipelines, causing errors, failed joins, and unreliable insights. Whether you’re dealing with inconsistent formats like YYYY-MM-DD, MM/DD/YYYY, or text-based dates like 'Oct 25th', cleaning and standardizing dates is crucial for ensuring data quality.
In this blog post, we’ll explore how to handle date formatting challenges using Databricks and PySpark. From parsing text-based dates to converting Excel serial numbers, you’ll learn practical techniques to clean your data and build reliable pipelines.
Why Fixing Date Formats Matters in Databricks
In distributed data environments like Databricks, your data often comes from multiple sources, each with its quirks. Here’s what you might encounter:
One source uses the ISO 8601 format:
YYYY-MM-DD.Another source sticks to U.S. formatting:
MM/DD/YYYY.And then there’s the wildcard—text-based dates like
'Oct 25th'or integers like45000representing Excel serial dates.
If these formats aren’t standardized, you’ll run into issues with joins, aggregations, and downstream reporting. Fixing date formats up front ensures your pipelines run smoothly and your insights are accurate.
How to Handle Date Formatting in PySpark
1. Parsing Standard Date Formats
To convert standard formats like MM/DD/YYYY into a consistent format (YYYY-MM-DD), PySpark provides the to_date function. Here’s how:
from pyspark.sql.functions import to_date
# Sample data
data = [('12/26/2024',)]
df = spark.createDataFrame(data, ['raw_date'])
# Convert MM/DD/YYYY to YYYY-MM-DD
df = df.withColumn('formatted_date', to_date('raw_date', 'MM/dd/yyyy'))
df.show()

Databricks Example code and output for converting US dates to ISO standard dates.
2. Formatting Dates for Reporting
Need to display dates in a specific format? Use PySpark’s date_format function. For instance, converting a date to 'December 26, 2024':
from pyspark.sql.functions import date_format
# Format the date for display
df = df.withColumn('display_date', date_format('formatted_date', 'MMMM dd, yyyy'))
df.show()
display(df)

Databricks / pyspark date formatting example.
3. Handling Unix Epoch Time
Unix Epoch time stores dates as the number of seconds since January 1, 1970. PySpark’s from_unixtime function is awesome for converting these types of date/time formats.
from pyspark.sql.functions import from_unixtime
# Sample data with Epoch timestamps
data = [(1706303400,)]
df = spark.createDataFrame(data, ['epoch_time'])
# Convert Epoch time to a readable date
df = df.withColumn('readable_date', from_unixtime('epoch_time'))
df.show()

**4. Cleaning Partial Dates Like 'Oct 25th'
Text-based dates like 'Oct 25th' can be tricky to handle. PySpark allows you to clean and parse these using functions like regexp_replace and concat.
from pyspark.sql.functions import regexp_replace, concat, lit, to_date
# Sample data
data = [('Oct 25th',)]
df = spark.createDataFrame(data, ['raw_date'])
# Clean and parse partial dates
df = df.withColumn('clean_date', regexp_replace('raw_date', 'th', '')) \
.withColumn('complete_date', concat('clean_date', lit(' 2024'))) \
.withColumn('parsed_date', to_date('complete_date', 'MMM dd yyyy'))
df.show()

Databricks / pyspark example of converting partial text dates to a ISO standard date.
5. Converting Excel Serial Dates
Excel stores dates as serial numbers representing days since January 1, 1900. Here’s how to convert these to readable dates:
from pyspark.sql.functions import expr
# Sample data
data = [(45000,)] # Represents March 15, 2023
df = spark.createDataFrame(data, ['serial_date'])
# Convert Excel serial dates to readable dates
df = df.withColumn('excel_date', expr("date_add('1900-01-01', CAST(serial_date - 2 AS INT))"))
df.show()
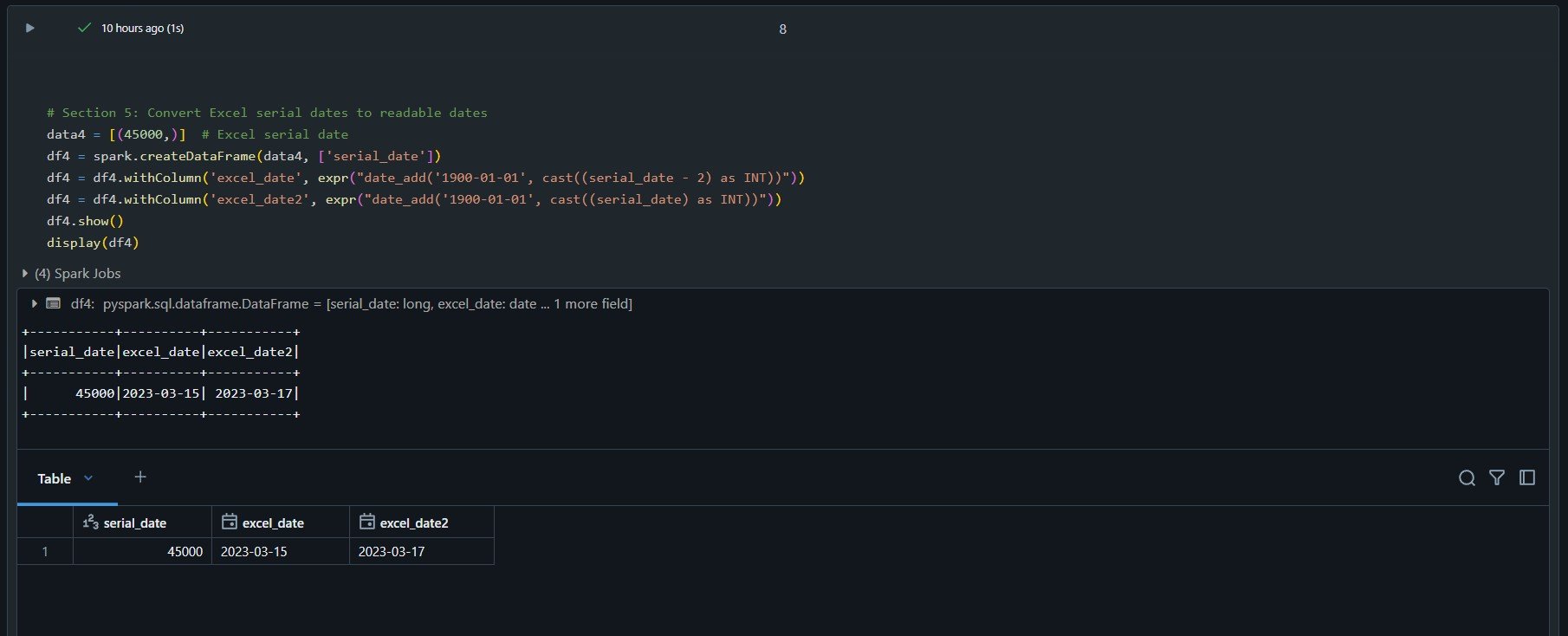
Databricks / pyspark - converting excel serial dates to ISO standard dates.
Best Practices for Handling Dates in Databricks
Standardize Early: Convert all dates into a consistent format (like
YYYY-MM-DD) at the start of your pipeline.Validate Inputs: Catch null or invalid dates before processing to avoid errors downstream.
Document Your Assumptions: Be explicit about how you handle partial or messy dates.
Test for Edge Cases: Include leap years, ambiguous formats, and outliers in your tests.
Conclusion
Whether you’re cleaning Unix Epoch time, Excel serial dates, or inconsistent formats like 'Oct 25th', PySpark in Databricks offers powerful tools to simplify the process. By mastering these techniques, you’ll ensure high-quality data pipelines that are scalable, reliable, and easy to maintain.
💡 What’s the trickiest date format you’ve dealt with? Share it in the comments on YouTube below—I’d love to hear your examples!
If this guide helped, share it with your team and check out my YouTube channel for more practical PySpark tutorials!