
Adding Actutal Intelligence To Your Data Engineering AI Agents
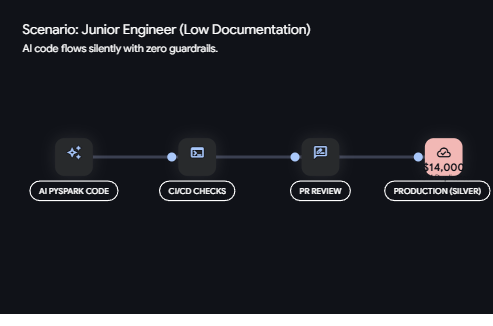
AI has revolutionized how we approach data engineering tasks. Yet, where AI offers speed and efficiency, it can also introduce significant risks if not properly guided. Let's explore a real scenario: A junior engineer deployed an AI-generated PySpark notebook to transfer data from the bronze to silver layer. The syntax? Flawless. The code passed CI/CD checks, received a PR approval, and then, silently, it duplicated 40 million records. The aftermath? A $14,000 cloud compute bill. This incident highlights a crucial point: AI lacks the understanding of historical load patterns, and without such context, costly mistakes can occur. In this post, we'll guide you through creating an AI skills documentation to prevent similar pitfalls in your data engineering endeavors.
Understanding the Context
Step One: Establish Your Standards Directory
Think of the standards directory as your enterprise memory. This is where you clearly outline boundaries: from naming conventions like Snake Case versus proper case to your policies on PII handling. Document required data contracts and specific use cases. Such documentation ensures the AI doesn't fall back on generic anti-patterns that disrupt your warehouse operations. Junior engineers might view AI as a syntax generator, while seniors often critique AI with skepticism. The truth is, coding is simple; understanding the context is challenging. AI works within a context vacuum, unaware of your specific standards, schemas, or data handling practices, which leads to issues such as maintenance nightmares, compliance breaches, and legal risks. Start by documenting your standards and governance rules in detail, and if you haven't already, make this your top priority.
Step Two: Develop Templates for Governance
Create templates that enforce complete governed solutions. AI should be instructed to generate not only random Python code but also accompanying notebooks, YAML files, and data quality checklists. Whether ingesting from an API, database, file store, or cloud storage, standardize your approach. Your approaches should be modular, reusable, and repeatable, allowing AI to continually employ proven patterns. Failure in design is acceptable only if accompanied by robust recovery strategies. Without referencing your enterprise masking policies, AI might mishandle sensitive data, introducing compliance breaches and organizational frustrations. Hence, AI must be treated as a partner, requiring comprehensive context for informed decision-making.
Step Three: Integrate into Executable Logic
Make your standards actionable by building programmatic integration skills that guide AI agents to query your data catalog, like the Unity catalog, for exact schemas and lineage before commencing coding. This strategy removes schema hallucinations and offers a potent synergy between your engineering team and AI. Imagine the impact of being able to download all metadata about your data landscape into a team member's mind instantaneously. Establishing clear pathways to access the heart of your platform empowers both human and AI agents with critical insights.
Evaluating and Auditing
Step Four: Establishing Evaluation Trails
Define your evaluation criteria rigorously in your skills documentation. Just as a junior engineer's PR requires tests before merging, AI-generated code should adhere to specific infrastructure rules and undergo thorough evaluations. Consider various data sets, use cases, and levels of aggregation, documenting and auditing this information to ensure consistent implementation across your data ecosystem. Log volume changes, data quality, and key metrics over time. By year's end, you'll be able to report tangible improvements in data quality and back it up with robust statistics. Though setting up this infrastructure demands a few extra days of architecture work upfront, it saves substantial costs compared to litigations and reduces tech debt, enhancing the maintainability of your code and enforcing consistency across your data platform.
Conclusion
A completed skills documentation, even if not comprehensive at the start, offers immense value. Begin with existing documentation and progress toward addressing critical risks, articulating your foundational security policy, and building these documents at the outset. Your AI agent and data team will evolve conjointly. For those aiming to develop anti-fragile pipelines, this post serves as both a guide and a call to action: document effective patterns for your data engineering agents now. Embrace AI as a crucial partner and safeguard your organization's data operations for a future of resilience and innovation.
